Similar to how Amitabh Bachchan’s profile was compromised, Sami’s profile picture with a photo of Pakistan Prime Minister Imran Khan.
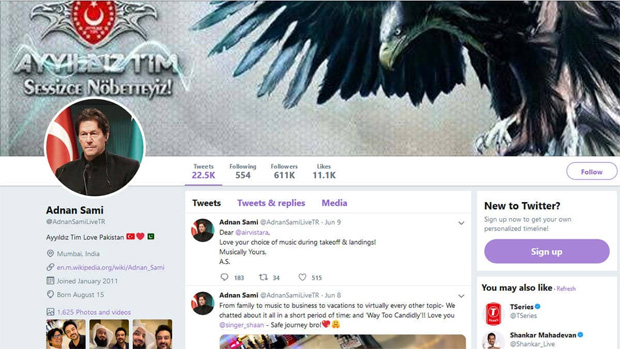
Singer Adnan Sami’s Twitter account was allegedly hacked on Tuesday by Ayyildiz Tim, the same Turkish hacker group that attacked megastar Amitabh Bachchan’s microblogging page a day ago. Similar to how Bachchan’s profile was compromised, the group replaced Sami’s profile picture with a photo of Pakistan Prime Minister Imran Khan and changed the bio, adding “Ayyildiz Tim Love Pakistan” with an emoji of Pakistani and Turkish flags.
Sami previously held a Pakistani passport and received Indian citizenship in 2015. Late Monday night around 11:40pm IST, the same group hacked into Bachchan’s account, also tweeting the link of its ‘official’ Instagram page, though unverified, writing “We are waiting for your support.”
Bachchan’s page was restored within half-an-hour after the Mumbai Police alerted the cyber unit. The group had previously hacked Twitter accounts of actors Shahid Kapoor and Anupam Kher among others as well.
A spokesperson for Mumbai Police told PTI that they have informed the cyber-unit and the matter is being investigated. The cover photo of Bachchan’s account, which was subsequently deleted, showed the promo picture of the group with an eagle in flight – the same case as Adnan Sami’s account.
“This is an important call to the whole world! We do condemn the irrespective behaviours of Iceland republic towards Turkish footballers. We speak softly but carry a big stick and inform you about the big Cyber attack here. As Ayyildiz Tim Turkish Cyber Army,” read the first tweet after the attack on Monday.
Source: (gadgets.ndtv.com)